
Concept and background information
Basically Anymeta allows you to store, retrieve and modify data with the following constraints:
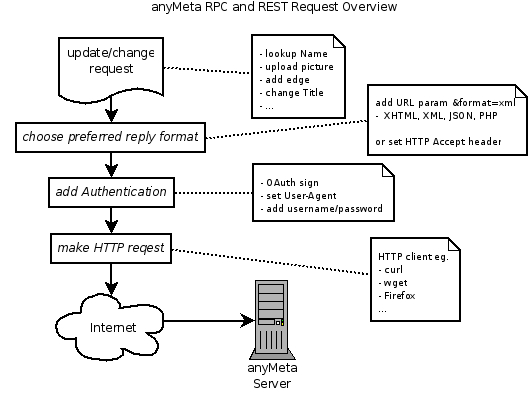
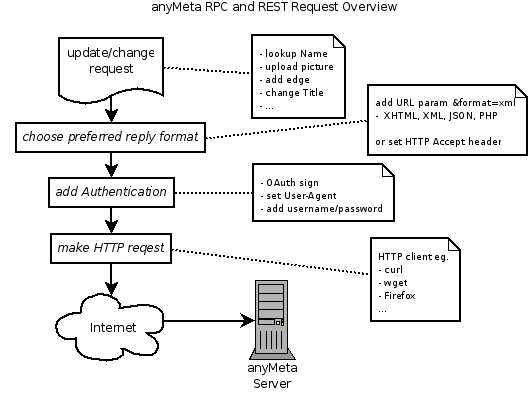
- Traffic is sent via HTTP requests.
- Querying information is subjected to access control, both for web-browser and bot.
- Access can be obtained by signing your request with OAuth.
- Data retrieval operations are should use the GET method
- Data modification operations must use the POST method
- You need choose a format (eg. HTML, JPEG, XML, JSON) to represent the thing(s).
Anymeta API overview
in Anymeta everything is a thing; meaning every person, article, object, role, attribute, etc is represented as a thing with an unique reference-handle (numeric ID or URL). Things can be connected by edges (links). Each of these edges consists of a predicate (eg "author of") and optionally attributes (eg. "language") linking a source object to a destination object. Both predicate and attributes are things themselves. - example : "John Doe" "is the author of " "article Foo" .
Every thing is reference by it's ID. There is a search function to lookup IDs by title and most functions allow to specify a symbolic name as a convenient shortcut (predicates like "author of" might be represented by different IDs or URIs on different systems and would require additional lookups beforehand). Custom modules allow to search RFIDs or perform more complex queries. Anymeta3 also accepts UUIDs and URIs as IDs for many requests but only Anymeta4 implements a compatible URI schema. anymeya4 even goes one step further and allows to discover the available services.
View the auto-generated API documentation to get an overview of all available calls. The most important ones are explained here as well:
| ~API~ | ~Explanation~ |
| anymeta.predicates.get | Get a specific data field, for instance the title of a thing. |
| anymeta.thing.dump | Get a full data-dump of a thing, including all references to its images, video files, etc. |
| anymeta.attachment.create | Create an attachment, e.g. upload an image or video into the system |
| anymeta.edge.add | Connect things in the database using edges, semantical links between things. |
| anymeta.search.live | Full-text search on the database |
| query.execute | Advanced, powerful interface for querying the semantic network and the thing database. |
| identity.search | Search the Identity database which stores RFID -- ID links |
| identity.add | Add an identity (e.g. an RFID tag) to the system |
Current applications
An overview of some of the applications which have been developed and which interact with Anymeta.
- All Social RFID games developed during the Mediamatic Hackers Camp at PICNIC'08 interface with Anymeta, one way or another (see the source code)
- The photo/videobooth - Cocoa Mac application (SVN)
- anyIdentity (SVN) - QT4 application supporting RFID registration, API call testing
- friendDrinkStation (SVN) - aka. Andy's python boozer.
Interfacing with the API
Use Python! ;-) An open source library has been released which make life very easy. See the 55696 article which explains all about it.
Low-level
All interaction is done through simple HTTP calls to the API controller.
For API interactions which need authentication, requests need to be signed with the OAuth standard, so using any OAuth implementation together with a HTTP libary (e.g. curl) will do the trick as well.
Mediamatic has been developing its own OAuth implementation for PHP, which is now one of two popular PHP oauth implementations on the net. Furthermore, for other languages, success has been reported with the JavaScript oauth library, with the liboauth C libary, the Cocoa OAuth consumer, and many others.
{kind=link}
{kind=link}